What Is a Relational Database Management System?
A database is a set of data stored somewhere, organized in a schema (we’ll discuss this in more detail later on). A relational database is a database that allows administrators and users to set up connections among different data records, and to use those connections to view and manage data. A database management system (DBMS) is the software used to query and view the data in the database, and a relational database management system (RDBMS) is the software used to do the same in a relational database. While there are separate functions for the database (data storage, data schema) and the DBMS (storage management, query processing), the two parts work hand-in-glove and are generally considered a single unit.
What Are Relational Databases Used For?
Relational databases can be used for everything from simple tasks like storing artist, album, and song information for a music retailer, to more complex activities like a financial institution’s records of stock and bond trades and other transactions for its customer base.
Relational databases are a good tool for managing a large amount of information because of their built-in scalability and flexibility. They also allow you to easily add new categories to the schema, don’t require you to update the software, and won’t impact existing data.
RDBMSs allow businesses to work with managerial data, like employees or customers, as well as transactional data, like sales or purchases. Management Information Systems are specialized implementations of databases.
RDBMSs are flexible in many ways and allow users to do the following:
- View and manipulate data to fit their own needs (they don’t restrict the user to preset views).
- Easily add or delete data categories as business needs change.
Relational Database Terms
Below are the unique terms and specific definitions that will help you understand what a RDB can do and how it works:
- Row: A set of data constituting a single item. For example, the data for a single employee (e.g. first name, last name, employee ID, hire date, work location, etc.) of a company would be displayed in a row. A row can also be called a record, an entity, or a tuple.
- Column: Labels for elements of rows. A column gives context to the information contained in rows. For an employee database, the column headers could be the items listed above for employees. A column is also known as an attribute or a field.
- Table: A group of rows that match the parameters set up for the table. The data in a table must all be related. An employee database may have separate tables for active employees, retired employees, and former employees. A table is also known as a relation or base revelar.
- View: A set of data based on a query via the RDBMS; also known as result set or derived revelar.
- Domain: The set of possible values for a given column. For example, the phone number and ZIP code columns would be numbers, while first and last names would be limited to letters.
- Constraint: A narrowing of a domain. For example, the domain of the work location on a employee record would be alphanumeric, but it could be restricted to a predefined list rather than being a free-form field. The phone number field would be constrained to 10 digits.
- Primary key: The unique identifier of a row in a table.
- Foreign key: The unique identifier of a row in another table.
- Distributed Database: A database that stores data in multiple locations, rather than on a single hard drive or server.
More About Keys
Primary keys and foreign keys are used to identify rows or records in a table. With a unique value to identify each record, it’s easy to build relationships between records in different tables. Rows can be in a table in any order, but are easy to find because of keys.
There are a few ways to ensure a unique value for each key when a new data record is added to a table:
- Generate One: Keys can be created based on an algorithm. It could be a random or sequential number, or based on the data in the record. An employee ID might be generated by taking the first and last initials of the employee’s name, and then adding a number. For example, Hans Henderson might get employee ID HH001, and Hiroko Hirai HH002.
- Create One: You can combine columns to create a unique key. To create a key for a list of work locations, you should be able to create a unique value by combining the name of the building and its ZIP code.
- Enter One: A user can type a value when entering the data. However, ensure uniqueness by putting business rules and data checks into place.
A key that has no relation to the data (such as a random or sequential number) is called a surrogate key. One based on the data is called a natural key.
An alternate key is a secondary unique identifier for a record or row. These are used for sorting, filtering, or viewing data within a table, but not for creating a relationship with data in another table. Alternate keys are often formed by combining the values in several columns.
A row or rows in one table can be linked to a row or rows in other tables by adding a column that contains the key for the linked row(s), thus creating relationships. Foreign keys in the referenced table match the primary key in the base table. The foreign key in the referenced table doesn’t have to be unique, which allows the creation of one-to-many and many-to-many relationships (we’ll talk more about relationships in the next section).
Primary keys become foreign keys when they are referenced in tables other than the one where they originated.
Types of Database Relationships
The power of a relational database is in the links and relations. By connecting rows in different tables through the use of primary and foreign keys, you can create views, reports, and other slices of information to serve your organization. There are three primary types of database relationships:
- One-to-One: One row in one table is connected to one and only one row in another table. For example, a Social Security number is linked to a single employee.
- One-to-Many: One row in one table is connected to zero, one, or more than one rows in another table. For example, one work location can be linked to many employees.
- Many-to-Many: Zero, one, or many rows in one table are linked to zero, one, or many rows in another table. For example, multiple employees can be assigned to multiple projects.
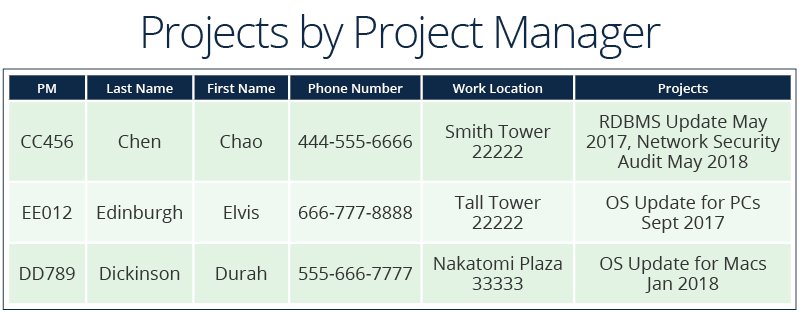
In the examples below, data is grouped into four tables: Employee, HR Data, Work Location, and Projects.
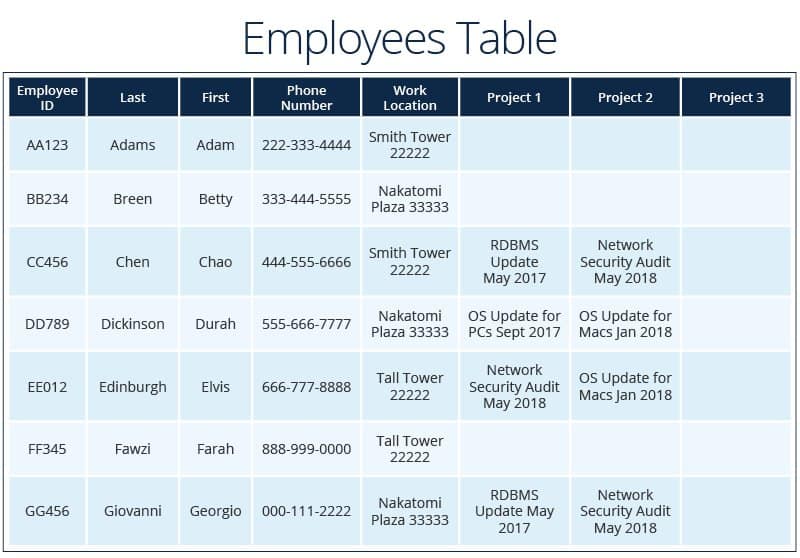
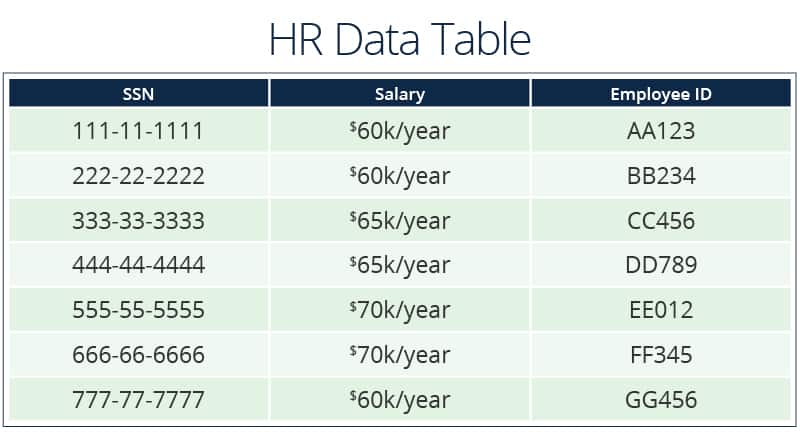
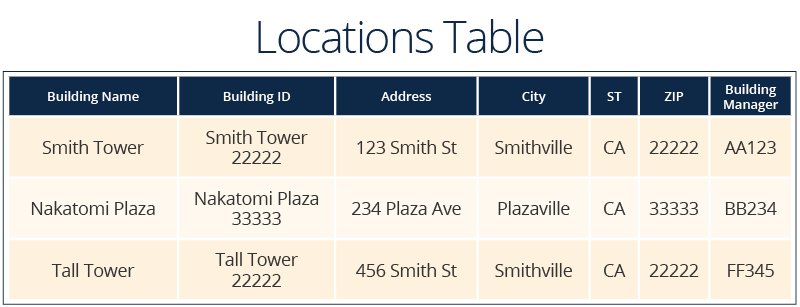
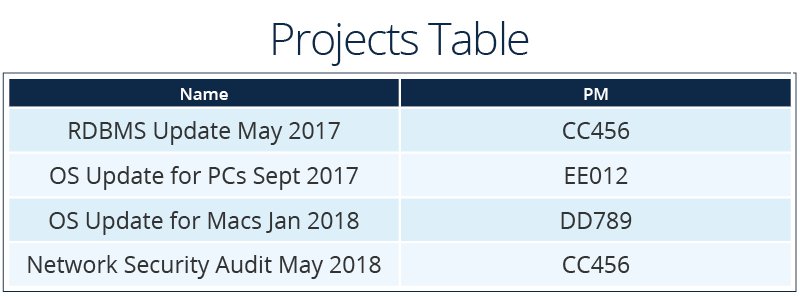
The example tables also demonstrate three ways to have a unique primary key:
- The primary key for the Employee table is Employee ID, which is generated. Two people could have the same name. A phone number is unique, but if someone moves to a new work location, that might change. A generated value is static and unique.
- The Locations table’s primary key is a calculated value. The Building ID column combines the building name and the ZIP code. Buildings in different cities might have the same name or address, so this calculated values guarantees that it’s unique.
- The Projects table uses the Name column as the primary key, which would be entered by an employee.
The tables in this example also contain illustrations of each kind of relationship.
One-to-One Relationship:
- Employee to HR data. This could easily be added as a column to the Employee table, but for security reasons, some data is stored in a separate table. A person using the database to find all employees working in one location doesn’t need to see their salaries or SSNs.
- Building managers to locations. Because the building manager is an employee, it makes sense to link to the employee data rather than recreating it in the building table.
One-to-Many Relationship:
- Project managers to projects. Each manager can be assigned to multiple projects.
- Work locations to employees. Each location can have multiple people working there.
Many-to-Many Relationship:
- Employees to projects. Employees can be assigned to multiple projects, and each project can have multiple people working on it.
More detailed information on database relationships can be found here.
Using Data to Create Views
With the example tables, admins could create different views for different user groups. Views often have basic query functionality built in, so users can customize details like dates, amounts, or locations. Below are some examples of different user needs:
- Directors want to see all employees assigned to their key project, their work location, and the phone number, plus who the project manager is.
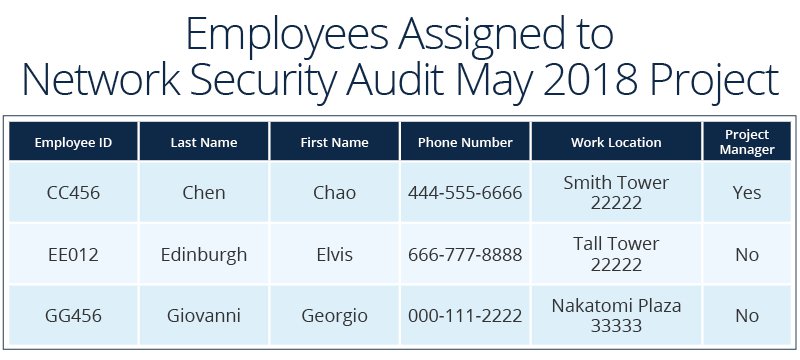
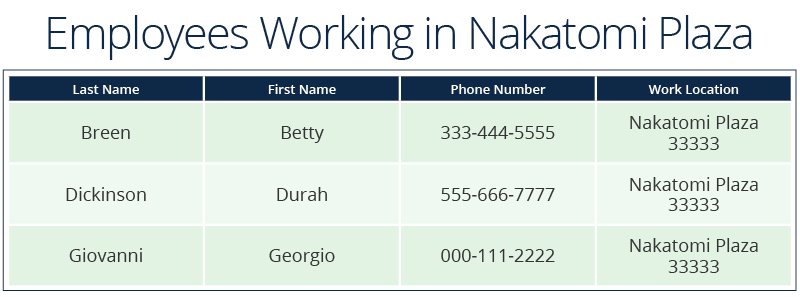
- Corporate real estate wants to see how many employees are assigned to a particular work location, plus their contact information.
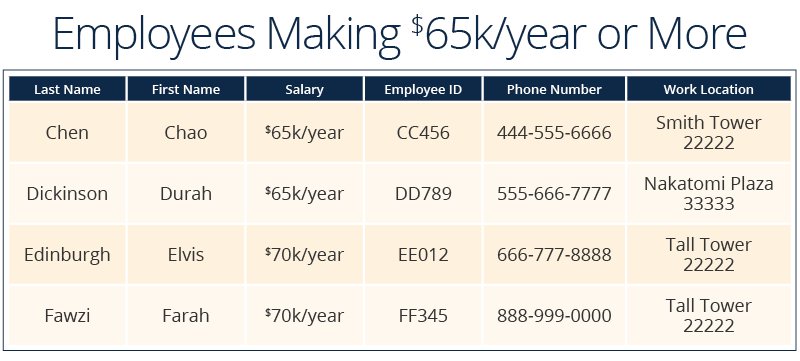
- HR wants to know which employees make a certain salary or more, plus their contact information, but doesn't want to display their Social Security number.
- A VP wants to see each project, the project manager, their contact information, and their work location.
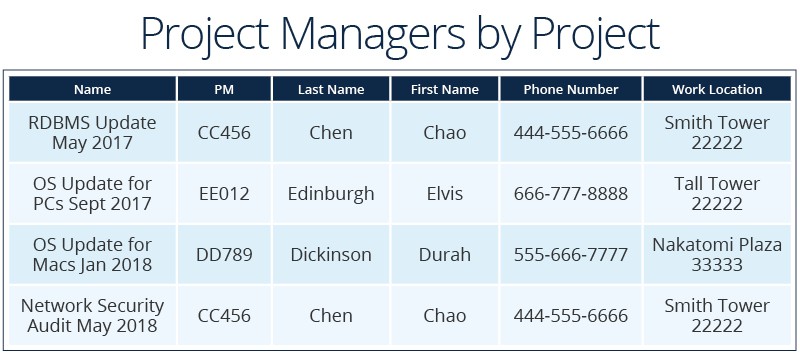
- Another VP wants to see the same information, but with the project manager as the key piece of data.
What Are Some Common DBMSs?
SQL (Structured Query Language)
SQL (pronounced “sequel”) is the most commonly used RDBMS. It’s based on SEQUEL (Structured English QUEry Language), a language created at IBM by Donald D. Chamberlin and Raymond F. Boyce, based on Edgar F. Codd’s relational model (more information below). In 1979, Relational Software, Inc. (later known as Oracle) released the first commercial SQL version. SQL has been in use for so long because it’s easy to learn, ubiquitous, and stable, and it performs well. There are open source variations, so the barrier to entry is low. Because it’s so popular, there is a lot of support available for people learning it or needing help.
Variations of SQL
There are a few different versions of SQL. The differences are mostly in syntax rather than function. Here is a list of common versions:
- MySQL (open source)
- SQL Server (Microsoft)
- SQLite (open source)
- Oracle Database (Oracle)
Other DBMSs
There are many DBMSs — some of these DBMS types are explored later in this article. Some popular non-relational databases include:
- PostgreSQL, an object-relational DBMS
- MongoDB, a document-oriented DBMS
- Redis, an in-memory key-value DBMS. In-memory means the data is stored in a computer’s main memory rather than on a disk, which allows for faster operations.
- Cassandra, a NoSQL DBMS
Others include IBM DB2 (relational), IBM Informix (relational), SAP Sybase Adaptive Server Enterprise (relational), SAP Sybase IQ (relational), Teradata (relational), Microsoft Access (relational), and Elasticsearch (search engine).
What Are the Most Popular DBMSs?
The answer to this question depends on whom you ask and what methodology each source uses. Here’s a review of rankings from Stack Overflow, ServerWatch, and DB-Engines:
RDBMS | Stack Overflow Developer Percentage | ServerWatch Ranking | DB-Engines Ranking (November 2017) |
|---|---|---|---|
RDBMS Oracle Database | Stack Overflow Developer Percentage 16.50% | ServerWatch Ranking 1 | DB-Engines Ranking (November 2017) 1 |
RDBMS Microsoft SQL Server | Stack Overflow Developer Percentage 38.60% | ServerWatch Ranking 2 | DB-Engines Ranking (November 2017) 3 |
RDBMS IBM DB2 | Stack Overflow Developer Percentage NA | ServerWatch Ranking 3 | DB-Engines Ranking (November 2017) 6 |
RDBMS SAP Sybase ASE | Stack Overflow Developer Percentage NA | ServerWatch Ranking 4 | DB-Engines Ranking (November 2017) 14 |
RDBMS PostgreSQL | Stack Overflow Developer Percentage 26.50% | ServerWatch Ranking 5 | DB-Engines Ranking (November 2017) 4 |
RDBMS MariaDB Enterprise | Stack Overflow Developer Percentage NA | ServerWatch Ranking 6 | DB-Engines Ranking (November 2017) 18 |
RDBMS MySQL | Stack Overflow Developer Percentage 55.60% | ServerWatch Ranking 7 | DB-Engines Ranking (November 2017) 2 |
RDBMS Teradata | Stack Overflow Developer Percentage NA | ServerWatch Ranking 8 | DB-Engines Ranking (November 2017) 12 |
RDBMS Informix | Stack Overflow Developer Percentage NA | ServerWatch Ranking 9 | DB-Engines Ranking (November 2017) 25 |
RDBMS Ingres | Stack Overflow Developer Percentage NA | ServerWatch Ranking 10 | DB-Engines Ranking (November 2017) 51 |
RDBMS MongoDB | Stack Overflow Developer Percentage 21% | ServerWatch Ranking NA | DB-Engines Ranking (November 2017) 5 |
RDBMS Microsoft Access | Stack Overflow Developer Percentage NA | ServerWatch Ranking NA | DB-Engines Ranking (November 2017) 7 |
RDBMS Redis | Stack Overflow Developer Percentage 14.10% | ServerWatch Ranking NA | DB-Engines Ranking (November 2017) 9 |
RDBMS Cassandra | Stack Overflow Developer Percentage 3.10% | ServerWatch Ranking NA | DB-Engines Ranking (November 2017) 8 |
RDBMS Elasticsearch | Stack Overflow Developer Percentage NA | ServerWatch Ranking NA | DB-Engines Ranking (November 2017) 10 |
Notes:
- The top 10 from each source are included (Stack Overflow only listed 7).
- DB-Engine uses a multiparameter ranking system.
- Stack Overflow surveyed its readers.
ServerWatch did not list its ranking criteria.
Challenges and Criticisms of Relational Databases
While RDBMSs are powerful and useful, they aren’t all sunshine and rainbows. The following are problems to be aware of with setup and use:
- RDBMSs can be complicated to implement.
- Performance issues can be difficult to predict, especially when the data is shared among multiple applications.
- It’s difficult to maintain data integrity when the data is shared among multiple applications.
- Different design strategies are required for operational databases versus reporting databases.
History and Evolution of Databases
The term “database” was first used in the 1960s. The history of databases can be divided into three eras, based on the dominant data model:
- Navigational: Data is stored in files, and is accessed by navigating through a tree-like structure. There were two versions: hierarchical (data is organized in a tree structure) and network (data is organized in a lattice structure).
- Relational: Data is stored in tables and is accessed via commands that display and combine records.
- Post-relational: This will be explored later in this article.
Early DBMSs were GE’s Integrated Data Store and IBM’s Information Management System.
Computer scientist Edgar F. Codd created the principles for the relational model while working at IBM in the 70s; this model led to the creation of relational databases. The model, outlined in a 1970 paper titled A Relational Model of Data for Large Shared Data Banks, says that data can be stored tuples (or rows) and grouped into relations (or tables); tuples can then be connected to tuples in other relations.
This paper led IBM to create System R in 1974, which was the first real-world application of the relational model and the first use of the language SEQUEL. The first commercial relational database was Oracle, released in 1979 by Relational Software Inc.; the company later changed its name to Oracle Systems Corporation.
Codd’s 12 Rules
In the 80s, E. F. Codd created a list of rules that defined his vision of a relational database. The list is called Codd’s 12 Rules (though in reality there are 13 because he started numbering at zero rather than one). The intent of the rules was to ensure that RDBMSs were in sync with the relational model he created. It’s hard to find a definitive source that lays out how well RDBMSs follow all the rules, but most online sources say that few commercial RDBMSs are fully compliant. Under a loose interpretation, an RDBMS can considered relational if it complies with at least two of Codd’s rules. Under stricter interpretations (by such people as database theorist Christopher J. Date and computer scientist Hugh Darween), systems that don’t comply with all rules are considered pseudo-RDBMSs.
Number | Title | Text |
|---|---|---|
Number 0 | Title The Foundation Rule | Text For any system that is advertised as or that claims to be a relational database management system, that system must be able to manage databases entirely through its relational capabilities. |
Number 1 | Title The Information Rule | Text All information in a relational database is represented explicitly at the logical level and in exactly one way: by values in tables. |
Number 2 | Title The Guaranteed Access Rule | Text Each and every datum (atomic value) in a relational database is guaranteed to be logically accessible by resorting to a combination of table name, primary key value, and column name. |
Number 3 | Title Systematic Treatment of Null Values | Text Null values (distinct from the empty character string or a string of blank characters and distinct from zero or any other number) are supported in a fully relational DBMS for representing missing information and inapplicable information in a systematic way, independent of data type. |
Number 4 | Title Dynamic Online Catalog Based on the Relational Model | Text The database description is represented at the logical level in the same way as ordinary data, so that authorized users can apply the same relational language to its interrogation as they apply to the regular data. |
Number 5 | Title The Comprehensive Data Sublanguage Rule | Text A relational system may support several languages and various modes of terminal use (for example, the fill-in-the-blanks mode). However, there must be at least one language whose statements are expressible, (per well-defined syntax) as character strings, and that is comprehensive in supporting all of the following items:
|
Number 6 | Title The View Updating Rule | Text All views that are theoretically updatable are also updatable by the system. |
Number 7 | Title High-Level Insert, Update, and Delete | Text The capability of handling a base relation or a derived relation as a single operand applies not only to the retrieval of data but also to the insertion, update, and deletion of data. |
Number 8 | Title Physical Data Independence | Text Application programs and terminal activities remain logically unimpaired whenever any changes are made in either storage representations or access methods. |
Number 9 | Title Logical Data Independence | Text Application programs and terminal activities remain logically unimpaired when information-preserving changes of any kind that theoretically permit unimpairment are made to the base tables. |
Number 10 | Title Integrity Independence | Text Integrity constraints specific to a particular relational database must be definable in the relational data sublanguage and storable in the catalog, not in the application programs. |
Number 11 | Title Distribution Independence | Text The end-user must not be able to see that the data is distributed over various locations. Users should always get the impression that the data is located at one site only. |
Number 12 | Title The Nonsubversion Rule | Text If a relational system has a low-level (single record at a time) language, that low level cannot be used to subvert or bypass the integrity rules and constraints expressed in the higher-level relational language (multiple records at a time). |
The Third Manifesto
Date and Darween published a book in 2006 called Databases, Types, and The Relational Model: The Third Manifesto, now in its third edition. In their first two manifestos, they talked about their vision for databases, DBMSs, and data. In the third, they build on that and focus on the data integrity problems that arise when RDBMSs and other kinds of DBMSs are accessing the same data (this is known as impedance mismatch). They also argue that SQL is inadequate and should be replaced.
Relational Databases vs. Nonrelational Databases
Besides relational, there are a number of other database design models and plenty of reasons why a nonrelational database might be better. These include (but are not limited to) the following:
- A data model that isn’t supported by a relational schema
- Scalability and performance issues
- Records that don’t fit well into the relational model
Before diving into these alternative databases, a couple of terms need to be defined:
- Object: In a relational database, an object is a table, column, or relationship. In object-oriented models, objects can be defined by the developers to meet the needs of the business.
- Object-oriented: A modular design approach that relies on creating and reusing objects. In databases, data is organized into objects rather than tables.
Type and Description | Strengths | Weaknesses |
|---|---|---|
Type and Description Flat file: Each file is independent, with no connection between them. Example: FileMaker (until 1994) | Strengths - Inexpensive - Good for smaller systems | Weaknesses - Users can't easily search entire database - There's no way to link data that are in different files - Inefficient memory usage |
Type and Description Object-oriented: The focus of an OODBMS (also written as ODBMS) is on data as objects rather than as relational tables. In an OODBMS, each object is a unit, rather than broken up among different tables. In an employee database, "employee" might be considered an object and all data about each object is stored together. The object also combines data and procedures (such as an operation to give a raise or change their job title); this is called encapsulation. Example: db40 | Strengths - Good when there are many complex data relationships - Easier navigation - Data model is similar to the real world | Weaknesses - Lower efficiency when the data is simple - Requires complex programming - No ad-hoc queries |
Type and Description Object-relational: A hybrid of object-oriented and relational database models. Examples: IBM Informix, IBM DB2, PostgreSQL | Strengths - Extensibility | Weaknesses - Impedance mismatch due to differences in how object-oriented and relational systems work - Complex programming |
Type and Description Columnar: Data is stored in columns rather than in rows. There is little functional difference between storing data in columns rather than in rows if the data is being accessed by a RDBMS. Examples: SAP (formerly Sybase) IQ, Druid | Strengths - Data can be compressed - Uses less disk space - Quick operations | Weaknesses - Slow data load times |
Type and Description Multi-dimensional: An MDNMS is optimized for online analytical processing (OLAP), data warehousing, and decision support systems. The data often comes from relational databases. The cube (or hypercube) is the key concept. (Imagine similar tables stacked on top of each other.) Each table might be a record of sales broken out by month, or the planned sales data and the actual sales data. Example: Arbor Essbase | Strengths - Natural language queries - Ease of maintenance due to the data structure - Fast performance | Weaknesses - Updates and searches can be challenging - Slow data load times |
Type and Description NoSQL: NoSQL may mean "not only SQL" (i.e., it uses SQL as well as non-SQL operations) or "not SQL." There are many subtypes of NoSQL databases. Common ones are listed below.
| Strengths - Design simplicity - Many operations are faster than in SQL - More flexible data modeling than SQL - Scalability - Works well with big data - Hardware costs can be lower | Weaknesses - Less mature than SQL - Harder to use for analytics and business intelligence - Less support available for developers -May not support normalization, unions, or joins |
Type and Description Document-oriented database: Designed to manage documents. Data in documents is called semi-structured data. An XML database is a type of document-oriented database. Example: MongoDB | Strengths Same as NoSQL | Weaknesses Same as NoSQL |
Type and Description Key-value: As with flat file, data is stored in one file rather than in a collection of tables (called an array, dictionary, or hash). Each data point has a unique key, like in a relational database table, but there is no data schema. Example: Redis | Strengths Same as NoSQL | Weaknesses Same as NoSQL |
Type and Description Wide column stores: Data is stored in rows and columns like an RDB, but the names and data constraints in columns can vary from row to row. Examples: Apache Cassandra, Hadoop | Strengths Same as NoSQL | Weaknesses Same as NoSQL |
Type and Description Graph stores: Uses natural structure of data rather than one imposed by a design or schema. The name comes from graph structure, a mathematical concept that is beyond the scope of this article. Examples: Teradata Aster, FlockDB | Strengths Same as NoSQL | Weaknesses Same as NoSQL |
How Relational Databases Operate
Basic Functionality
The basic functions of a DBMS are to read (view data via queries), create (add data, tables, rows, or columns), update (change data, tables, rows, or columns), and delete data. Conditions can be added to perform more functions such as the following:
- View data that meet certain criteria. A store manager could view all items that have fewer than 10 units in stock, or that have been in the warehouse for more than three months.
- Create a new table that is a subset of a base table. The marketing department could create a table that shows only customers who live within a 10-mile radius of a new location.
- Connect the contents of two different tables. A contractor could view all the subcontractors who worked on a project and the amount each billed for their work, or a principal could see all students who have a GPA of 3.5 or better.
- Combine data in two tables: HR could view all actives employees and all retired employees to create an invitation list for the company holiday party.
- View data that have no relationship: This might be a list of all customers who created an account but who never placed an order, then delete them.
- Add new data to existing records: Find all customers who’ve ordered more than $1,000 worth of products in a year and give them an automatic discount on their next order.
- Delete data from existing records: Delete the automatic discount from customer accounts after its expiration date.
Some Common SQL Commands
To accomplish the actions above, database developers and admins use the commands listed below to query or update the database:
- ALTER TABLE: Adds new columns to an existing table.
- BETWEEN: Filters results based on two parameters — e.g., view employees whose birthdays are between June 1 and June 30, or all cars that cost between $20,000 and $25,000.
- CREATE TABLE: Adds a new table to the database. Parameters are added to the command to specify the number and names of the columns.
- DELETE: Removes rows from a table.
- JOIN: Allows the data from multiple tables to be combined. Read more about SQL JOINS here.
- INSERT: Adds a new row to a table. Parameters are added to the command to specify the data in the columns.
- LIMIT: Sets the maximum number of rows that will be displayed when querying a database. You could see the best-selling books of 2014, but limit it to the top 10.
- ORDER BY: Sorts the results by a certain column. For example, when looking at the 10 top-selling books of 2014, you could sort the list by title, by the author’s last name, or by sales volume.
- SELECT: All SQL queries begin with SELECT.
- UNION: Combines the results of multiple queries.
- UPDATE: Edit rows in a table.
- WHERE: A conditional statement that allows queries, additions, deletions, and changes to be limited to data that meet certain criteria. The BETWEEN, LIMIT, and ORDER BY examples above would be accomplished by using WHERE. It could also be used to limit rows removed in a DELETE command.
Data Models, Designs, and Schemas
A database model is an abstract representation of how data will be stored. It shows how data elements will be organized and the relationships between them. The term is also used to describe high-level concepts like relational, flat-file, or object-relational database systems.
A database schema is the implementation of the data model (the first sense above) in the database. It includes data types, constraints, and keys (both primary and foreign).
Database design is the production of a database model (again, in the first sense above) based on the needs of the users.
Locking
When data is being modified, locking prevents another user or transaction from altering that data. This prevents data from falling out of sync.
Database Normalization
Database normalization is the foundation of relational databases. It’s the process that organizes data into tables that can then be connected to each other. Each table should be about a specific topic, and only those columns that support the topic are included in the table.
Database normalization provides the following benefits:
- Duplicate data is minimized, and data storage needs decrease.
- Changes to data have to occur in only one place.
- Access to the data is quicker and more efficient.
Once the data schema and business rules for the database are established, the data is processed in steps that create tables and primary keys, eliminate repetitive data, and build relationships between the data by splitting the data into new tables and creating foreign keys for those tables. The steps are called First Normal Form (1NF), Second Normal Form (2NF), and Third Normal Form (3NF). Each step attempts to further refine the data and narrow the focus of each table.
Complicated data schemas may require fourth and fifth normal forms. There are variations of forms, such as the Boyce–Codd Normal Form (BCNF), which is a more robust version of the 3NF and is used in unique situations.
A full description of the normalization process is beyond the scope of this article, but an excerpt from the 2002 book Absolute Beginner's Guide to Databases by John Petersen, available on the informIT website, covers it well.
Null and Duplicate Values
Null values are data points that don’t exist. For example, not everyone has a middle name, a customer may not provide a phone number, or data may have been lost. A relational database must accommodate these exceptions to rules (it’s the third of Codd's 12 Rules). Null values do not equal zero or a space. However, a null row should not be allowed, even though some RDBMSs do.
Duplicate values will exist. There may be two employees with the same first and last name, and maybe even the same birthday. That’s OK. But having duplicate rows that match, including the key, is not. Again, some RDBMSs allow this, but it violates the basic principles of a relational database.
Database Security
There are a few facets to database security, all of which are vital to database operations:
- Ensuring that users can see only the data they are authorized to see and use only commands they are authorized to run
- Keeping unauthorized users from accessing the database
- Detecting and stopping malware and other attacks
- Preventing data corruption
- Ensuring database availability by preventing system crashes
Detailed information on the second and third concepts can be found here.
Views and Reports
A view is a generally a screen or a set of screens that is customized to show data that meet the needs of a specific user group, and prevents them from seeing data they don’t have access to. Views can allow users to query the contents of the database without having to know any SQL or other commands.
Reports are queries that are run and delivered to a person or group that can be used to guide business decisions. Reports can be scheduled or ad-hoc, and can show either real-time data or data from the past (such as the previous week or quarter).
Transactions and Stored Procedures
Transactions occur when data is added, updated, or deleted. Relational database transactions should follow the ACID guidelines, meaning they should be:
- Atomic: The transaction is indivisible, or all operations in the transaction must occur, or the transaction fails and all changes must be rolled back to their original state.
- Consistent: All steps must meet the defined rules for any changes to data fields, record uniqueness, data constraints, etc.
- Isolated: Data that’s being changed by the transaction can’t be updated by other transactions or by users until the first transaction is completed or cancelled.
- Durable: Once the transaction is complete, the changes must not be lost in the event of a power outage or other catastrophic event.
Examples of transactions could include adding an order record to a table once a customer hits the buy button, or changing the work location of an employee if they've moved from one office to another.
Stored procedures are compiled pieces of code that usually perform a number of defined steps. Code runs faster when it compiled (i.e., when it’s been translated from the developer's programming language into machine language). A stored procedure can include transactions. An example of a stored procedure might be a monthly sweep to move customer records from an active customer table to an inactive table if the customer hasn’t purchased anything in the last year.
Coupling: A measure of the amount of dependence between two items. A column of data (e.g., employee birth date) is tightly coupled to any stored procedure (e.g., “show all employees who have a birthday in the coming month”) that will reference the column, so changes to one will impact the other. If all dates are changed to a new format, but the stored procedure isn’t updated, employees won’t get their cake.
Data integrity: Also known as data quality. Data should be complete, accurate, and correctly formatted; if it’s not, it can be useless (or even harmful). Ensuring data integrity is a key part of database design.
Referential integrity: This is an important subset of data integrity. Every column in a table that holds a foreign key must contain a null value or a value in another table that is considered that table’s primary key. These are the basic rules:
- A key (primary or foreign) must match the key in a row in another table, or be null.
- If a primary key in one table changes, all tables where that key is listed as a foreign key must be updated.
- If a row is updated, all rows linked to that row must be deleted or relinked to other rows.
Metadata
Metadata are data about the database itself. Just like data, metadata are stored in tables, but only used by the DBMS. As data is added, deleted, or changed, the metadata is updated. The metadata allows the DBMS to find data, create new tables, manage resources, and enforce security.
Fine-Tune Your Database Management System with Smartsheet
Empower your people to go above and beyond with a flexible platform designed to match the needs of your team — and adapt as those needs change.
The Smartsheet platform makes it easy to plan, capture, manage, and report on work from anywhere, helping your team be more effective and get more done. Report on key metrics and get real-time visibility into work as it happens with roll-up reports, dashboards, and automated workflows built to keep your team connected and informed.
When teams have clarity into the work getting done, there’s no telling how much more they can accomplish in the same amount of time. Try Smartsheet for free, today.